이 글은 Byzantine Fault 문제에 대해 간략하게 제가 공부한대로 다뤄본 글입니다. 잘못된 부분에 대한 지적이나 글에 대한 코멘트, 그리고 스타벅스 아메리카노 기프티콘을 달게 받고 있습니다.
- The Byzantine Generals Problem
- Practical Byzantine Fault Tolerant algorithm (1)
- Practical Byzantine Fault Tolerant algorithm (2)
- Other BFT approaches, and Blockchain
PBFT Algorithm
[1]은 Miguel Castro가 1999년 USENIX OSDI에 발표하고 PhD 졸업논문으로까지 발표한 논문입니다. 이 알고리즘은 Byzantine Fault를 견딜 수 있는 분산 합의 알고리즘의 대명사급으로 쓰이며, 최근 컨소시움형 블록체인 프로젝트인 Hyperledger Fabric에서 채용한 것으로도 주목을 많이 받고 있습니다.
이 알고리즘은 Byzantine Fault를 일으키는 노드가 있는 상황에서 State Machine Replication을 목표로 합니다. 구체적으로, N=3f+1대의 노드가 있는 클러스터에서 최대 f대의 노드가 동시에 Byzantine Fault를 일으킬 때에도 정직한 노드들은 같은 상태로 전이하는 것을 목표로 합니다.
System Model
Network Model
이 논문에서는 클러스터 안의 노드들끼리 서로 네트워크로 연결되어 있으며, 모든 노드는 클러스터 안의 다른 모든 노드들의 public key를 알고 있다고 가정합니다. 또한 네트워크는 Asynchronous하다고 가정합니다. Asynchronous한 네트워크로 인해 일어날 수 있는 현상으로는 아래와 같은 것들이 있습니다.
- 메세지를 보냈으나 메세지 전달이 늦어질 수도 있습니다.
- 메세지를 보냈으나 메세지 전달에 실패할 수도 있습니다.
- 똑같은 메세지가 두 번 갈 수도 있습니다.
- 메세지가 도착하는 순서가 뒤죽박죽(out-of-order)이 될 수 있습니다.
다만, 완벽히 asynchronous한 네트워크1는 이 논문에서 가정하지 않습니다. 단 한 대라도 죽은 서버가 있으면 완벽히 asynchronous한 네트워크에서 합의가 불가능하기 때문입니다[2]. 이 논문에서는 메세지가 아주 오랫동안 도착하지 않는 경우를 가정하지 않으며, 네트워크에 문제가 있을 경우 담당자가 재빨리 뛰어들어 네트워크를 고치고 클라이언트가 결국 response를 받을 수 있는 일반적인 상황을 가정합니다.
Failure Model
위에서 언급한 것과 같이, Byzantine Failure 모델을 가정합니다. 클러스터 안에 서버가 최소한 N=3f+1대가 있는 상황에서 동시에 최대 f대의 서버가 fail할 수 있는 상황을 가정하고 있습니다.
그리고 독립적인 서버의 실패를 가정하고 있습니다. 이 말은 어떤 서버가 실패하면 다른 서버도 덩달아 실패할 수 있는 가능성을 완전히 차단하겠다는 말입니다. 즉, 프로세스끼리 간섭하는 경우 없도록 노드별로 root 패스워드가 전부 다르게 설정되어있는 경우만을 생각합니다.
마지막으로 어떠한 서버도 다른 서버의 서명을 따라할 수 없도록 충분히 강력한 비대칭 키를 이용하여 서명하는 것을 가정합니다.
Protocol of PBFT
Notation
자세한 프로토콜 설명에 들어가기 앞서, 이 문서에서 앞으로 전자 서명이나 해쉬를 어떻게 표기할 것인지를 약속하고 넘어가겠습니다.
- (M)si: 메세지 M을 i의 secret key si로 서명하여 보내는 것을 말합니다.
- D(M): 메세지 M을 해쉬하여 구한 digest를 말합니다.
Rough sketch of the algorithm
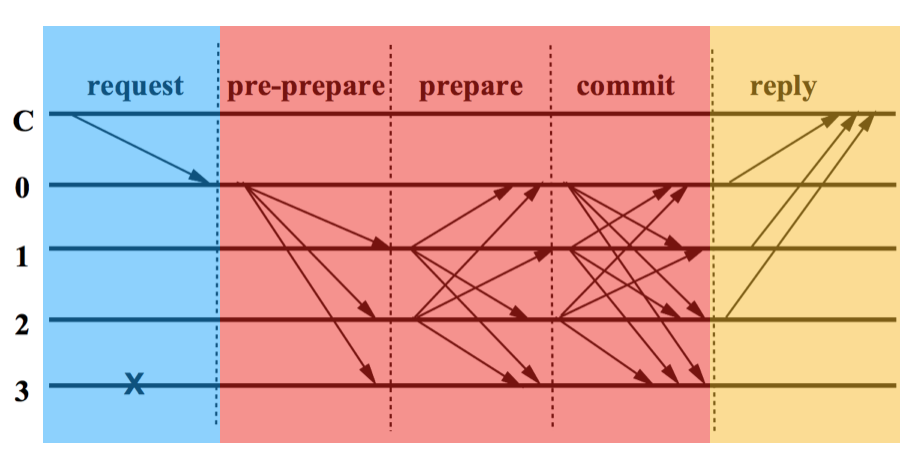
이 알고리즘이 어떤 순서로 작동하는지를 먼저 나열해보겠습니다.
-
클라이언트는 primary 노드에게 요청을 보냅니다. (위 그림의 파란 부분)
-
primary 노드는 나머지 노드에게 클라이언트의 요청을 전파하고 합의 과정을 거칩니다. (위 그림의 빨간 부분)
-
각 노드는 합의 과정에서 클라이언트의 요청이 클러스터에 반영되는 것이 확실해지면 클라이언트에게 요청에 대한 답변을 줍니다.
-
클라이언트가 f+1개 이상의 똑같은 답변을 받으면 요청이 제대로 반영되었다는 것을 확신할 수 있습니다. (위 그림의 노란 부분)
합의 과정은 총 3단계로 구성되어 있으며, 각각
PRE-PREPARE,PREPARE,COMMIT이라고 부릅니다. 각 단계에서 어떤 일들이 일어나는지, 각 단계 진행중에 문제가 생기면 어떻게 핸들링하는지 이제부터 알아봅시다 :3
View, Primary, Backup
시작하기 앞서, 몇 가지 개념을 정의합시다.
- View: primary 노드 p가 primary 노드로서 활동하는 기간의 단위를 의미합니다. view v의 primary는 v mod N번 노드가 담당합니다. Raft의 term number와 유사한 개념입니다.
- Primary: 클라이언트로부터 메세지를 받고, 이 메세지의 순서를 정해주는 역할을 합니다.
- Backup: 클러스터의 primary를 제외한 다른 모든 노드들을 의미합니다.
Request
우선 클라이언트가 요청을 클러스터로 보냅니다. 클라이언트는 클러스터에 요청을 보낼 때, 요청하고 싶은 operation o와 클라이언트 자신의 타임스탬프 t와 클라이언트를 식별할 수 있는 id인 c와 함께 서명하여 (REQUEST, o, t, c)sc 라는 메세지를 클러스터의 primary에게 보냅니다.
Pre-prepare Phase
Primary가 유효한 request를 클라이언트로부터 받으면 request에 sequence number라고 부르는 숫자 n을 붙입니다. Sequence number는 “몇 번째 request”인지를 나타냅니다. 예를 들어 sequence number가 97인 request는 97번째로 도착한 request를 나타내겠죠.
Request를 받은 primary는 다른 모든 노드에게 ((PRE-PREPARE, v, n, d)sp, m)이라는 메세지를 보냅니다. 이 메세지의 의미는 다음과 같습니다.
- 메세지 m이 클라이언트로부터 도착했어요.
- 거기에 primary인 p가 PRE-PREPARE 단계에 primary가 해야할 일을 했답니다. 이 일의 증거를 m에 piggy-back으로 보내겠습니다.
- View number v, Sequence number n으로 메세지 m을 인정할 겁니다.
- m이 조작되지 않았음은 m의 hash digest인 d로 확인하시면 됩니다.
- 이 메세지가 조작이 아님은 primary의 서명 sp로 보장하겠습니다.
Prepare Phase
Pre-prepare 메세지를 받은 backup은 우선 받은 메세지가 유효한 메세지인지 검증하는 단계를 거칩니다. 유효한 Pre-prepare 메세지란, 다음을 만족하는 메세지를 말합니다.
- Signature sp가 유효하며
- 현재 backup의 view인 v에 있는 메세지이고
- view v, sequence number n의 메세지를 받은 적이 없으며
- sequence number가 h < n < H 임. (h, H는 checkpoint 부분에서 설명하도록 하겠습니다.)
prepare 단계로 들어갑니다. 이 단계에서는 backup들이 (PREPARE, v, n, d, i)si라는 메세지를 클러스터 내의 모든 노드들에게 보냅니다(multicast). 이 메세지의 의미는 다음과 같습니다.
- primary 노드가 예전에 보냈던 메세지는 잘 받았습니다.
- 그 메세지의 hash digest는 d더군요.
- 그 메세지를 View number v의 sequence number n번 request로 받아들이겠습니다.
클러스터 안의 모든 노드는 자기가 보낸 prepare 메세지와 일치하는 prepare 메세지를 수집합니다. 우리는 앞으로 i번 노드가 메세지 m에 대해 view number v, sequence number n인 prepare message를 서로 다른 노드로부터 2f개를 수집하게 된 상태를 prepared(m,v,n,i) 라고 표현할 것입니다. 이와 관련하여 중요한 성질을 하나 만족합니다.
정직한 노드 i, j에 대해, prepared(m,v,n,i)면 D(m)!=D(m')인 메세지 m'에 대해 ~prepared(m',v,n,j)이다.
이 성질은 메세지의 반영 순서를 클러스터 내에서 합의했다는 의미를 담고 있습니다. 즉, Pre-prepare와 Prepare 단계는 메세지의 반영 순서에 관한 합의를 위한 단계라고 보시면 되겠습니다.
참고로, 이 알고리즘은 충분히 강한 Hash function을 사용한다고 가정하며, Hash collision을 고려하지 않습니다.
Commit Phase
노드 i는 prepared(m,v,n,i)가 참이 되면 (Commit, v, n, D(m), i)si라는 메세지를 보냅니다. 그리고 다른 노드들이 보내는 Commit 메세지의 서명을 검증하고 차곡차곡 저장해둡니다. 유효한 commit 메세지의 조건은 prepare phase에서 했던 것과 비슷하게, view number v와 sequence number n, 그리고 서명 검증을 합니다.
모든 정직한 노드가 성공적으로 메세지를 반영했다는 것은 어떻게 보장할 수 있을까요? 이를 알아보기 위해 먼저 다음 두 개의 용어를 정의하도록 하겠습니다.
- Committed(m,v,n): 메세지 m이 View number v, Sequence number n으로 f+1개의 정직한 노드가 prepare함.
- Committed-local(m,v,n,i): Prepare(m,v,n,i)이고 메세지 m을 View number v, Sequence number n으로 commit하겠다는 2f+1개의 commit 메세지를 받음 (자기 자신의 메세지 포함)

정직한 노드 i에 대해 Committed-local(m,v,n,i)가 참이라고 합시다. 이중에 잘못된 노드가 k개쯤 있다고 합시다. i에게 아직 commit 메세지를 보내지 않은 노드들까지 고려해봅시다. 이 노드는 최대 f개 있을 수 있겠죠? 이중에 h개는 잘못된 노드라고 하고, 나머지 f-h개의 노드는 정직한 노드라고 합시다. 우리가 처음 가정하기로, 동시에 f대의 노드까지만 잘못될 수 있다고 했습니다. 그래서 h의 최댓값은 f-k가 될 수 밖에 없고, 정직한 노드는 최소 k대가 남은 노드중에 존재할 수 있게 됩니다. 즉, 우리가 필요한 2f+1대의 합의는 마친 셈이죠! 그래서, 노드 i가 committed-local(m,v,n,i)를 만족하게 되면 이 때 메세지를 실행하게 됩니다. 그리고 client에게 각자 response를 보냅니다.
Back to client!
다시 클라이언트입니다! f+1개 이상의 똑같은 응답을 받으면 클라이언트는 자기 메세지가 클러스터에 제대로 들어갔구나! 하는 것을 확신할 수 있게 됩니다.
3줄 요약 + Next
- pBFT라는 byzantine fault tolerant한 알고리즘의 normal case에 대해 다뤘습니다.
- 3 phase로 이뤄져있습니다.
- 클라이언트가 메세지를 보내고 f+1개의 똑같은 답변을 받으면 안심할 수 있어요.
Normal case operation을 설명하다보니 글이 길어졌습니다. 남은 부분은 다음 글에서 작성해보도록 하겠습니다.
Footnote
1 완벽히 asynchronous한 네트워크는 다음과 같은 네트워크를 말합니다[2].
- 프로세스 모두에게 동일한 시각을 제공하는 시계가 없음
- timeout을 이용한 알고리즘 사용 불가
- 다른 프로세스의 죽음을 알 수 있는 방법이 전혀 없어 프로세스가 그냥 느리게 돌고 있는 건지 죽은건지 판단할 방법이 없음
References
[1] M. Castro, B. Liskov, “Practical Byzantine Fault Tolerance”, USENIX OSDI, 1999.
[2] M. Fischer, N. Lynch, and M. Paterson, “Impossibilify of Distributed Consensus With One Faulty Process”, Journal of the ACM, 32(2), 1985.
이미지들은 직접 만든 이미지이거나 [1]의 figure를 가져왔습니다.