이 글은 Byzantine Fault 문제에 대해 간략하게 제가 공부한대로 다뤄본 글입니다. 잘못된 부분에 대한 지적이나 글에 대한 코멘트, 그리고 스타벅스 아메리카노 기프티콘을 달게 받고 있습니다.
- The Byzantine Generals Problem
- Practical Byzantine Fault Tolerant algorithm (1)
- Practical Byzantine Fault Tolerant algorithm (2)
- Other BFT approaches, and Blockchain
Checkpointing
PBFT 알고리즘은 항상 안전성을 보장하기 위해 모든 메세지를 저장해야 합니다. 그렇지만 이렇게 계속 냅두면, 담아야 하는 메세지가 너무 많아지겠죠? 그래서 PBFT에서는 중간중간 안정된 체크포인트(stable checkpoint)를 만들어 최종 결과만 저장하고 필요 없는 메세지를 버리는 작업을 합니다.
체크포인트는 모든 노드가 (CHECKPOINT, n, d, i)si 라는 메세지를 보내며 만듭니다. 이는 i번 노드가 sequence number n까지의 메세지를 실행시켜서 도달한 state machine의 상태 state를 hash한 digest가 d라고 주장하는 메세지입니다. 자신의 메세지를 포함하여 최소 2f+1개의 digest가 같은 체크포인트 메세지를 받게 되는 순간 그 체크포인트는 안전하다고 보장할 수 있게 됩니다. 2f+1개의 체크포인트 메세지를 받은 노드는 체크포인트의 sequence number보다 작은 메세지를 모두 버립니다. 이 체크포인트 메세지는 체크포인트가 안전하다는 증거로 쓰이게 됩니다.
하지만 체크포인트를 만드는 일은 매우 많은 공이 들어가는 작업입니다! 모든 노드가 다른 모든 노드에게 체크포인트 메세지를 뿌리고, 그 메세지를 검증하고… 하는 작업이 들어가기 때문입니다. 그래서 모든 sequence number마다 하는 것은 무리가 있겠죠.
그럼 언제 체크포인트를 만들까요? Pre-prepare과 prepare phase의 h와 H 값을 기억하나요? 이 h와 H는 각각 low watermark, high watermark라고 불립니다. low watermark는 마지막 stable checkpoint가 커버하는 sequence number를 말합니다. 보통 적당한 간격 k를 잡아서 H = h + k로 설정하고, 메세지의 sequence number가 H가 되면 체크포인팅 작업을 하게 됩니다.
View Change
Client Interaction, Primary Fault Detection
어떻게 백업들이 primary의 실패를 감지할까요? 이 메커니즘을 파악하기 위해서는, 클라이언트와 클러스터 사이의 상호작용을 다시 한 번 되짚어볼 필요가 있습니다. PBFT에서는 클라이언트와 클러스터 사이에 어떤 상호작용이 있는지 다시 되짚어봅시다.
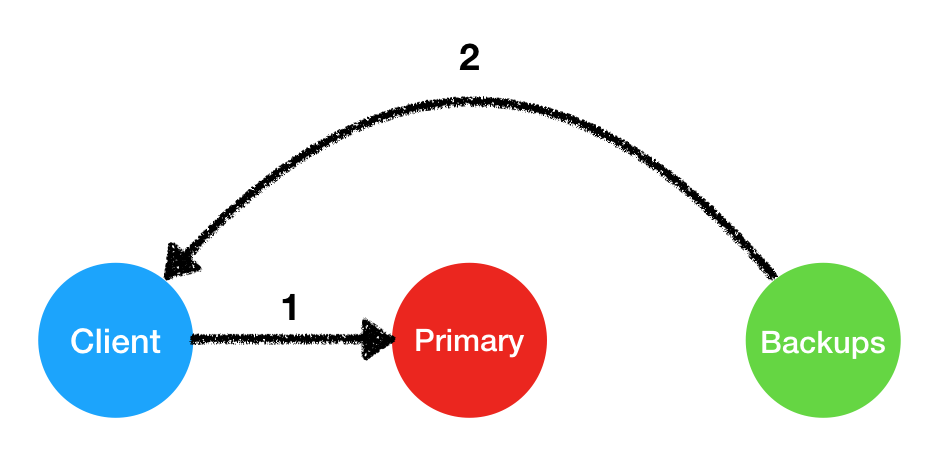
위 그림의 1과 같이, 클라이언트는 클러스터의 primary에게 request를 보냅니다. 하지만 네트워크 사정으로 메세지가 전달이 되지 않았을 수 있습니다. 혹은, 1의 링크는 정상적으로 동작하여 request는 잘 갔으나, 2의 링크가 정상 동작하지 않아 response가 클라이언트에게 도착하지 않았을 수도 있습니다.
link failure를 고려하여, PBFT에서는 primary의 fail을 3단계에 걸쳐서 감지합니다.
- 위 그림의 (1) 링크가 fail했다면 클라이언트는 일정 시간동안 단 하나의 response도 받지 못 하게 됩니다. 이 경우, 클라이언트는 클러스터의 모든 backup에게 request를 보냅니다.
- (2)의 링크가 fail했다면, 리퀘스트는 이미 commit된 상태일겁니다. backup은 이미 처리한 메시지라면 저장해둔 response를 다시 클라이언트에게 보냅니다.
- (1)의 문제도, (2)의 문제도 아니라면 backup은 해당 리퀘스트를 완전히 처음 보는 상태가 됩니다. 이 때 부터 primary의 실패를 의심하기 시작합니다. 각 backup은 request를 primary에게 전달하고, 그럼에도 불구하고 primary로부터 pre-prepare 메세지가 오지 않는다면 primary의 fail로 간주하고, view와 primary의 전환을 시작합니다.
View Change
Primary가 죽었습니다! 클러스터 내의 각 노드들은 primary 노드가 죽은 것을 타임아웃으로 눈치채고, 새로운 노드가 primary가 되어야 한다고 주장합니다. 그 주장은 (View-change, v+1, n, C, P, i)si 라는 메세지를 통해 합니다. 이는,
- 노드 i는 view가 바뀌어야 한다고 생각합니다!
- View를 v+1로 바꿀 것이고,
- 마지막 stable checkpoint의 sequence number가 n이고,
- sequence number가 n인 곳 까지 stable checkpoint가 만들어졌다는 증거는 C에 있고,
- 내가 갖고 있는 n보다 큰 sequence number를 가진 prepare 된 메세지와 그 메세지들이 prepare 되었다는 증거는 P에 있습니다!
라는 의미의 메시지입니다.
이전 글에서 언급했다시피, View v의 primary는 v mod N 번 노드가 담당하게 됩니다. 새로운 view가 될 노드는 본인 제외 2f개의 유효한 view-change 메세지를 받으면 자신이 새로운 view라는 메세지를 다른 모든 노드에게 전달합니다.
이 메세지는 (New-view, v+1, V, O)sp 입니다. 이 의미는,
- 새로운 view로 넘어갑니다!
- View number는 v+1입니다!
- 새로운 view로 넘어가는 증거는 2f개의 View-change 메세지 때문인데, 그 메세지는 V에 담아놨습니다!
- 필요한 pre-prepare 메세지는 O에 담아뒀습니다!
v+1과 V까지는 모두 이해가 가셨을 것이라고 생각합니다. O는 그러면 어떤 집합을 말하는 걸까요?
앞서 봤던 request의 반영이나 체크포인트 등을 다시 살펴보면, 모든 노드가 같은 메세지를 반영했다는 보장을 하기 전에 2f+1개 이상의 노드가 메세지를 반영하면 바로 반영하고 넘어가버리는 방식을 취하고 있습니다. 이때문에, 일부 노드의 stable checkpoint는 나머지 다수의 노드의 stable checkpoint와 다를 수도 있고, prepare된 메세지도 다를 수 있습니다.
O는 이런 노드 사이의 메세지 반영 상태의 차이를 메우기 위해 만들어지는 Pre-prepare 메세지의 집합입니다. O는 다음과 같은 과정으로 만들어집니다.
- View-change에 적혀있던 stable checkpoint의 sequence number 중 가장 작은 것을 min-s, prepare된 메세지의 sequence number중 가장 큰 것을 max-s라고 합시다.
- min-s < n <= max-s 인 모든 sequence number n에 대해서,
- sequence number가 n이고 prepare된 메세지 m이 있다면 (Pre-prepare, v+1, n, D(m))sp 을,
- sequence number가 n이고 prepare된 메세지 m이 없다면 (Pre-prepare, v+1, n, null)sp 을 넣습니다.
이 O라는 집합을 통해, 새로운 primary는 자기가 미처 따라잡지 못 한 체크포인트를 따라잡을 수 있게 됩니다. 다음 예제를 통해 어떻게 새로운 primary가 체크포인트를 따라잡는지 봅시다. Node 1이 다음 primary가 된다고 가정합시다.
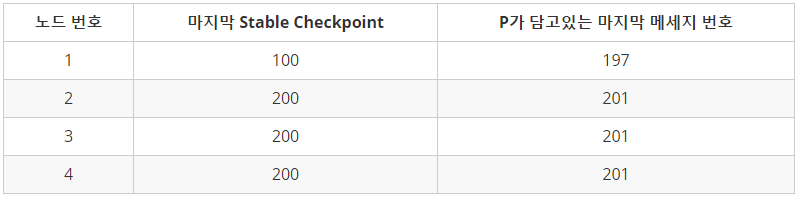
모종의 링크 사정으로 인해 2, 3, 4번 노드가 합의한 체크포인트인 n=200에 다다르지 못 한 1번 노드가 다음 primary가 되어야 합니다. O에는 101번부터 197번까지 메세지에 대한 Pre-prepare 메세지와, 198번부터 201번까지의 null 해시가 담긴 Pre-prepare 메시지가 담기게 될 것입니다. 1번 노드는 자기가 갖고있지 않은 request에 대해 O에 있는 엔트리를 이용하여 pre-prepare 메시지를 자신의 로그에 담아 sequence number를 201까지 채웁니다.
이제 1번 노드도 200까지의 체크포인트를 만들고 마지막 sequence number를 201까지 따라잡을 수 있습니다! 다만, 이 때 다른 노드가 실행했던 것을 또 한 번 실행하는 것은 아닙니다. 다른 노드로부터 201번 request까지 처리했을 때의 상태를 받아서 그 상태를 덮어씌우는 방식으로 체크포인트를 따라잡습니다.
이런 방식으로 새로운 primary는 new-view 메시지를 multicast하고, 다른 노드에서도 비슷하게 O를 계산하여 유효한지 검증한 후 새로운 primary를 받아들입니다.
Proof of Correctness
이 단락에서는 디테일을 생략한 증명의 큰 그림을 그립니다. 보다 상세한 증명은 [2]를 참조하시기 바랍니다.
Safety: Total Ordering of Requests
우리는 Pre-prepare phase와 Prepare phase를 통해 정직한 노드라면 같은 sequence number로 같은 메세지를 받아들인다는 것을 보인 바 있습니다. 즉, request의 순서는 정직한 노드들에 대해서 보장이 됩니다.
Safety: Requests Eventually Reaches Non-faulty Nodes
일부 정직한 노드에서 미처 커밋 못 했지만, 나머지 정직한 노드가 커밋한 메세지 m을 생각해봅시다. 만약 primary가 멀쩡한 상황이라면 나중에 언젠가 메세지가 도착해서 제대로 m이 도달할 겁니다. 하지만 그러지 않은 경우를 생각해봅시다. m을 커밋하지 못 한 노드들의 집합을 Mnc 라고 하겠습니다. Mnc 의 노드들은 m을 커밋하지 못 했지만, 위에서 소개한 View-Change 프로토콜을 통해 m의 sequence number에는 모두 동의하게 됩니다. 이 때 view number는 다르겠지만, 메세지 m이 sequence number n이라는 사실에는 모든 정직한 노드가 동의하게 된 것입니다.
또한, m이 commit되었다는 것은, committed-local 조건을 만족했다는 것이고, 이는 committed 조건을 만족했다는 의미 또한 됩니다. 즉, 여기서 우리는 최소 f+1개의 m을 커밋한 정직한 노드들의 집합인 R1 이라는 집합을 생각해볼 수 있습니다.
View-change 이후 New-view 프로토콜을 생각해봅시다. 새로운 primary가 new-view를 보내기 위해서는 2f+1(본인 포함)개의 view change에 동의하는 노드가 필요합니다. 이 노드들의 집합을 R2라고 합시다. 우리는 3f+1개의 노드가 있다고 가정했으므로, R1과 R2 두 집합 안에 모두 속하는 노드 k가 최소 하나 존재함을 알 수 있습니다.
이 k는 View-change 메세지에 직전 view에서 prepare된 메세지 m을 담아서 보내게 됩니다. 즉, Mnc 에 있는 노드들도 결국 메세지 m을 전달받게 된다는 것을 의미합니다. 이것으로 모든 노드가 같은 메세지를 같은 순서대로 전달받아 최종적으로 같은 상태로 들어간다는 것에 대한 증명의 큰 그림이 그려집니다.
Next
이번 포스트까지 해서 PBFT가 어떻게 Byzantine Fault Tolerant한 시스템을 만드는지 살펴보았습니다. 다음 포스트에서는 비트코인의 PoW와 이더리움의 PoS가 어떻게 Byzantine Fault Tolerance를 만들었는지 살펴보도록 하겠습니다. 또한 PoW의 몇몇 흥미로운 취약점들에 대해서도 다뤄보려고 합니다.
References
[1] M. Castro, B. Liskov, “Practical Byzantine Fault Tolerance”, USENIX OSDI, 1999.
[2] M. Castro, B. Liskov, “A Correctness Proof for a Practical Byzantine-Fault-Tolerant Replication Algorithm”, Technical Memo MIT/LCS/TM-590, MIT Laboratory for Computer Science, 1999.
이미지들은 직접 만든 이미지이거나 [1]의 figure를 가져왔습니다.