이 글은 USENIX ATC 2014에서 Best paper로 선정되었던 D. Ongaro et al.의 In Search of an Understandable Consensus Algorithm를 읽고 나름대로 제가 raft를 어떻게 이해했는지 정리해보는 글입니다.
이 글은 다음과 같은 시리즈로 작성될 예정입니다.
- 분산 시스템과 합의 알고리즘, 그리고 Raft의 디자인과 추구하는 방향
- Raft의 큰 그림: 용어 정의, 부분문제
- Raft의 부분 문제 - Leader election, Log Replication
- Raft의 안정성 증명
- 다시 Raft의 큰 그림, Raft 평가, 그 외 기타 이슈
혹시 이 글에서 틀린 점이 있다면 코멘트 부탁드리겠습니다.
Why Distrubuted System?
기존의 단일 서버 아키텍쳐에서는 몇 가지 문제가 있었습니다.
SPoF(Single Point of Failure)
“단일 실패 지점” 정도로 번역할 수 있겠습니다. 쉽게 말해서, 서버가 죽으면 모든 서비스가 통째로 죽는다는 뜻입니다. 이유는 간단합니다. 한 서버가 모든 비즈니스 로직을 관리하기 때문입니다. 그리고 거의 5년에 한 번 쯤, 서버는 거의 99% 죽습니다. 사람들은 같은 서비스를 담당하는 노드를 여러개 만들어서 분산 시스템을 구성하고, 이를 통해 노드 하나가 죽어도 resilent하게 작동할 수 있는 서비스를 구성하려고 노력합니다.
Throughput
단일 서버가 모든 리퀘스트를 처리하는 것을 상상해봅시다. 그리고 서비스를 시작한 지 어느정도 시간이 지나고, 폭발적으로 사용자가 늘어나는 행복한 상황을 상상해봅시다. 서버 한 대가 힘들어할 정도의 리퀘스트가 들어오기 시작합니다. 리퀘스트에 대한 리스폰스 타임이 점점 길어지기 시작합니다. 사용자들은 “운영자 일 안 하냐!” 하며 욕을 하기 시작합니다. 빠르게 대응하려고 비싼 램 비싼 랜카드 등등을 사봅니다. 그런데 이런 하드웨어 장비들은 퍼포먼스에 따라서 가격이 지수적으로 올라갑니다. 너무 비쌉니다. 여기서 scale-out이라는 아이디어가 생깁니다. 사람들은 같은 일을 처리하는 노드를 여러개 두고, 작업을 각 노드가 감당할 수 있을 정도로 나눠서 전체 성능을 올리기 위한 시도를 합니다.
이런 시도들은 대표적으로 GFS, HDFS, RAMCloud와 같은 상용 프로젝트에서 확인할 수 있습니다. 또한 우리가 자주 사용하는 torrent의 Distributed Hash Table에서도 확인할 수 있습니다.
Uncertainty Is an Evil
그렇지만 분산처리 방식의 가장 중요한 문제점이 있습니다. 각 노드가 노드 밖의 상황을 전혀 알 수 없다는 불확실성에 있습니다. Nancy A. Lynch 교수님은 아래와 같은 불확실성들을 언급합니다 [1].
- 이 분산 네트워크에 노드가 총 몇 개 있을까요?
- 이 분산 네트워크에 노드끼리 어떻게 연결되어있을까요?
- 노드끼리 다른 인풋을 받을텐데, 어떻게 그 인풋을 볼까요?
- 노드가 켜지고 꺼지는 시간이 다를 수 있고, 노드끼리 성능이 다를 수 있어요.
- 노드 A가 보낸 메세지는 노드 B에게
- 보내질까요?
- 언제 도착할까요?
- 노드 C가 보낸 메세지보다 먼저 도착할까요 늦게 도착할까요?
- 분산 시스템 열심히 돌리는데 아기상어가 랜케이블을 씹어먹어서 메세지가 안 가면 어쩌죠?
휴, 문제 많네요.
State Machine Replication Problem
노드끼리 불확실성이 이렇게 많은 와중에 우리는 노드끼리 같은 곳을 바라보고, 같은 생각을 하게 만들고 싶습니다. 여기서 시작된 문제가 바로 State Machine Replication Problem입니다. 문제를 한 줄로 정의해보자면 다음과 같이 정리할 수 있습니다.
- 우리가 돌리는 서버들의 레플리카들이 어떤 시점에서 같은 state machine의 같은 state를 계산하도록 만들 수 있을까?
- 서버 레플리카 몇 개가 죽어도 여전히 똑같은 state를 계산하도록 만들 수 있을까?
같은 State Machine의 같은 State를 계산한다는 말은, 쉽게 말해서 어떤 시점에 노드들이 같은 입력을 받고 일관적인 출력을 하냐 정도로 요약할 수 있겠습니다.
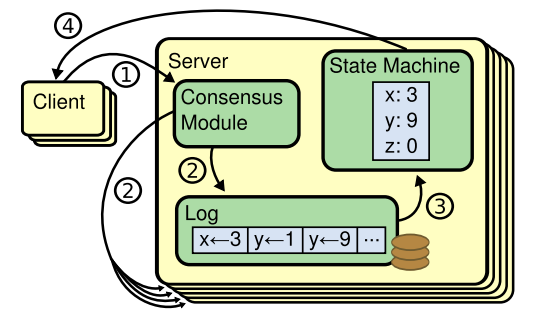
State Machine Replication은 일반적으로 분산 시스템에 들어온 로그를 복제하는 방식으로 구현합니다. 위의 그림과 같이, (1) 각 서버는 서버로 들어온 명령을 받고, (2) 합의하여 순서대로 로그로 남기고, (3) 로그에 따라서 State machine을 수행하여, (4) client에게 output을 보내주는 방식입니다.
위 그림의 (2)에서 나온 합의라는 게 그러면 무슨 뜻일까요? 바로 모든 서버의 레플리카에 대해서 로그를 일관성있게 유지한다는 것입니다. 합의 알고리즘(Consensus algorithm)들은 로그를 일관적으로 일관적으로 유지하는 알고리즘이겠죠.
Motivations and Design Choices
1998년 L. Lamport가 Paxos라는 합의 프로토콜을 발표했고[2], 십수년간 “합의”라는 말과 Paxos는 거의 같은 뜻으로 쓰였다고 해도 무방합니다. 그렇지만 Paxos는 너무 이해하기 어려워서 사람들이 실수하기 쉽다는 점이 치명적인 문제점이었습니다. 그래서 저자들은 이해하기 쉬운 합의 알고리즘을 만들어야겠다는 모티베이션으로 이 작업을 시작합니다. 구체적으로, 저자들이 이 논문에서 정해둔 목표는 다음과 같습니다.
- 이 알고리즘을 사용하는 사람들이 State Machine Replication 문제에 신경쓰지 않을 수 있도록 실제로 사용되는 분산 시스템을 만드는데에 필요한 기능을 모두 제공할 것
- 흔히 일어날 수 있는 모든 상황에서 안전하게 잘 작동하는 합의 알고리즘일 것
- 쓸만한 정도로 충분히 효율적인 알고리즘일 것
- 이해하기 쉬울 것
References
[1] Nancy A. Lynch “Distributed Algorithms” (pp. 2-3) Morgan Kaufmann Publishers, Inc.
[2] Lamport, L. “The Part-time Parliament” ACM Transactions on Computer Systems 16, 2 (pp. 133-169)
이미지들은 직접 만든 이미지이거나 원 논문의 figure를 가져왔습니다.