이 글은 USENIX ATC 2014에서 Best paper로 선정되었던 D. Ongaro et al.의 In Search of an Understandable Consensus Algorithm를 읽고 나름대로 제가 raft를 어떻게 이해했는지 정리해보는 글입니다.
이 글은 다음과 같은 시리즈로 작성될 예정입니다.
- 분산 시스템과 합의 알고리즘, 그리고 Raft의 디자인과 추구하는 방향
- Raft의 큰 그림: 용어 정의, 부분문제
- Raft의 부분 문제 - Leader Election, Log Replication
- Raft의 안정성 증명
- 다시 Raft의 큰 그림, Raft 평가, 그 외 기타 이슈
혹시 이 글에서 틀린 점이 있다면 코멘트 부탁드리겠습니다.
Revisit: Invariants of Raft
저번 포스트에서 Raft가 만족하는 성질들을 상기시켜드리고자 여기에 다시 남깁니다.
- Election Safety: 클러스터 안에 최대 1개까지 노드가 존재할 수 있음
- Leader Append-Only: 리더는 절대로 로그를 덮어쓰거나 삭제하지 않고 새 엔트리를 추가하기만 함
- Log Matching: 서로 다른 두 노드에서 같은 인덱스를 갖는 로그가 같은 term에 쓰여진 로그라면, 두 로그는 완전히 동일한 로그임
- Leader Completeness: 어떤 두 term T, U(U > T)에 대해, T에 커밋된 로그는 term U에서의 리더의 로그에도 커밋되어있음
- State Machine Safety: 클러스터 내의 임의의 서버 S1이 자기 서버의 Log[i]를 커밋했다면, 다른 모든 서버들의 Log[i]도 S1의 Log[i]와 일치하여 결론적으로 같은 명령을 수행함.
Assumptions, Failure Model
분산 시스템의 합의 알고리즘은 노드가 어떤 장애를 일으킬 수 있냐 가정하는 것에 따라 크게 세 가지로 분류합니다.
-
Fail-stop model
노드의 failure를 감지할 수 있으며, 고장났을 경우 네트워크에서 퇴출하는 모델
-
Fail-recovery model
노드의 failure과 timeout을 구분하지 않고, fail한 노드를 다시 부활시켜서 네트워크 안에서 다시 일하도록 할 수 있는 모델
-
Byzantine-fault model
위의 모델에서 말하는 failure는 알고리즘에서 정해진 규칙을 따르지만 서버가 crash되는 경우만을 고려하나, 이 모델에서는 소수의 서버가 고의로 규칙을 따르지 않고 임의의 output을 내는 경우까지 가정하는 모델
우리가 다루는 Raft의 failure model은 fail-recovery model이며, 각 노드가 네트워크에 참가한 노드를 전부 알고있는 상황을 가정합니다. 또한, 다음과 같은 부등식이 성립함을 가정합니다.
- Broadcast Time « Election Timeout « MTBF(Mean Time Between Failure)
이 부등식의 의미는 브로드캐스트는 리더가 죽었다고 판단할 수 있는 타임아웃보다 훨씬 빠르게 되고, 서버는 자주 고장나지 않아 새로운 리더 선출이 빈번하지 않다는 의미입니다.
Leader Election
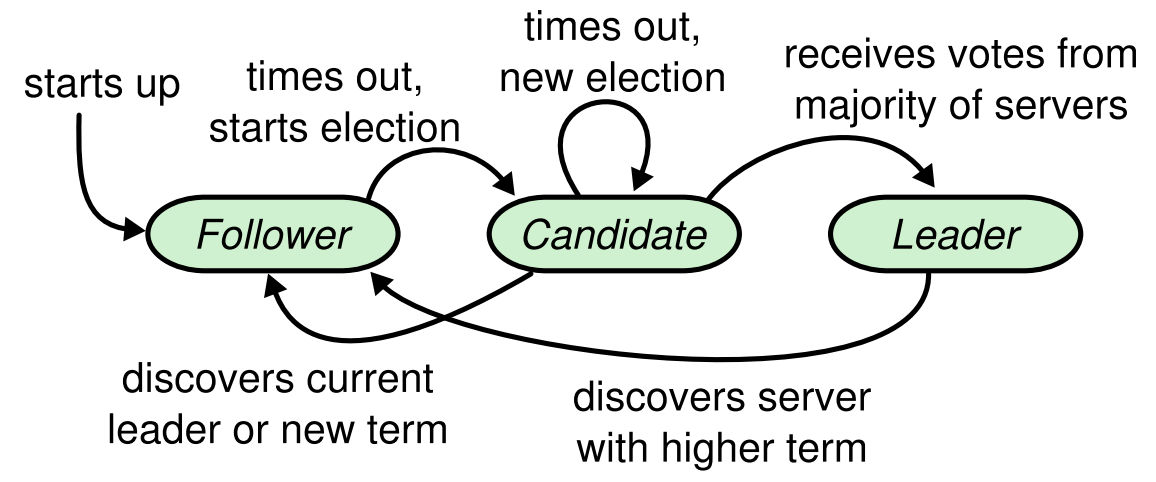
When the leader is alive
각 노드의 로그에 새로운 로그를 붙일 수 있는 노드는 리더노드 뿐입니다. 즉, 새로운 request를 받고 State Transition을 수행하기 위해서는 언제나 리더가 존재해야 한다는 의미입니다.
Raft에서는 Heartbeat 메커니즘을 이용하여 leader election을 시작합니다. 지난 포스트에서 언급했듯, 리더는 주기적으로 AppendEntries 라는 RPC 콜을 보냅니다. 리더는 이 RPC 콜을 통해 새로운 로그를 클러스터에 전파하는 것은 물론, 주기적인 RPC를 통해 리더가 살아있음을 알릴 수 있습니다.
Leader goes down and new vote begins
각 팔로워 노드들은 처음 켜질 때, 그리고 AppendEntries 를 받을 때마다 랜덤한 타임아웃을 겁니다. 이 타임아웃동안 리더로부터 AppendEntries 를 단 한 번도 못 받았을 경우, 리더 노드가 죽은 것으로 판단합니다. 참고로 이 논문에서는 150~300ms의 타임아웃을 이용한다고 언급했습니다.
팔로워 노드는 AppendEntries RPC 콜을 못 받아 리더가 죽은 것으로 판단하면 RequestVote RPC 콜을 이용하여 리더 후보 상태로 진입합니다. 이때의 term은 기존 리더의 term number보다 1 높아집니다. 쉽게 설명하자면, “k기 리더가 죽어서 k기 리더의 시대는 끝났다! 내가 k+1기의 리더가 될 것이다!”라는 메세지를 던지는 것입니다. 리더 후보는 클러스터의 노드들에게 과반의 찬성 response (respond positively)를 받으면 리더가 됩니다. 기본적으로 후보는 자기 자신에게 자동으로 찬성표를 던집니다.
팔로워 노드가 RequestVote RPC 콜을 이용하여 투표를 요청한 후보에게 찬성 Response를 주는 경우는 아래와 같습니다.
- 자기 자신보다 term number가 높을 것
- 다음 리더가 결정되기 전 이미 어떤 노드 v에게 찬성 투표를 했다면, v보다 term number가 높은 노드일 것
위의 경우를 제외하면 반대표로 후보에게 직접 응답을 줍니다.(respond negatively)
여기서 잠깐, 왜 팔로워들은 정해진 타임아웃이 아닌 랜덤한 타임아웃을 이용할까요? 그것은 선거가 부결되는 가능성을 최소화하기 위함입니다. 예를 들어 모든 노드가 똑같이 200ms의 타임아웃을 갖고 있다고 합시다. 이 경우 모두 후보가 되어 자기 자신에게 투표를 해달라고 RequestVote 를 날릴 것입니다. 모든 후보는 자기 자신에게 투표를 했을테고, 결국 과반의 표가 모이지 않겠죠. 반면, Raft의 설계와 같이 랜덤한 타임아웃을 가지는 경우를 생각해봅시다. 가장 작은 타임아웃을 가졌던 노드가 다른 노드가 타임아웃을 기다릴 동안 먼저 RequestVote 브로드캐스트를 할 것이고, 투표가 한 번에 끝날 가능성이 높아지게 됩니다.
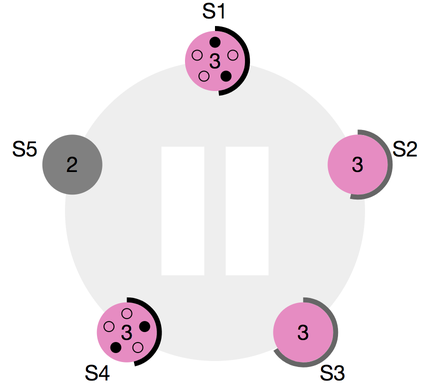
이렇게 해도, 여전히 선거가 부결될 가능성이 있습니다. 가령 위의 경우를 생각해봅시다. S1과 S4가 거의 동시에 후보가 되고 S5가 잠시 죽은 상황입니다. S1은 S3에게, S4는 S2에게 표를 얻었지만 어떤 후보도 과반의 표를 얻지 못 한 상황입니다. 위의 그림과 같은 경우 term 3의 선거는 망합니다.
선거가 망한 것을 알기 위해서 후보들도 팔로워들과 똑같이 랜덤한 타임아웃을 겁니다. term k에서 과반의 표를 얻은 후보가 아무도 없는 채로 후보나 팔로워중 타임아웃이 일어나면 그 노드에서는 새로운 term number인 k+1로 후보가 됩니다. 즉, term k에서는 리더가 없는 채로 지나가게 되는 것입니다. 이렇게 각자 랜덤한 타임아웃을 갖고 여러번 선거를 반복해서 후보가 뽑히지 않는 확률은 매우 낮아지게 되고, 결국 새 리더가 뽑히게 될 것입니다.
Log Replication
Log append
리더는 새로운 로그를 로그 엔트리에 추가할 수 있습니다. 하지만 기존에 받은 로그를 지우거나 수정할 수는 없습니다. 반대로 팔로워들은 새로운 로그를 직접 추가할 수 없고, 리더가 보내는 AppendEntries RPC를 통해서 받은 로그만을 자신의 로그 엔트리에 추가합니다. 대신, 항상 Log Matching Property를 만족하기 위해 팔로워는 적당히 로그를 삭제할 수 있습니다. 로그가 삭제되는 시나리오는 아래와 같습니다.
- S4가 현재 리더고, term 4에서 아직 전파되지 않은 로그가 몇 개 있습니다.
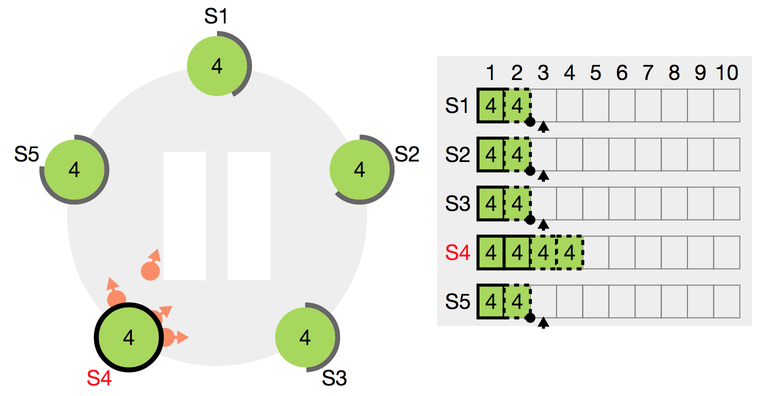
- S4가 전파되지 않은 로그를 미처 전하지 못 하고 뻗어버립니다!
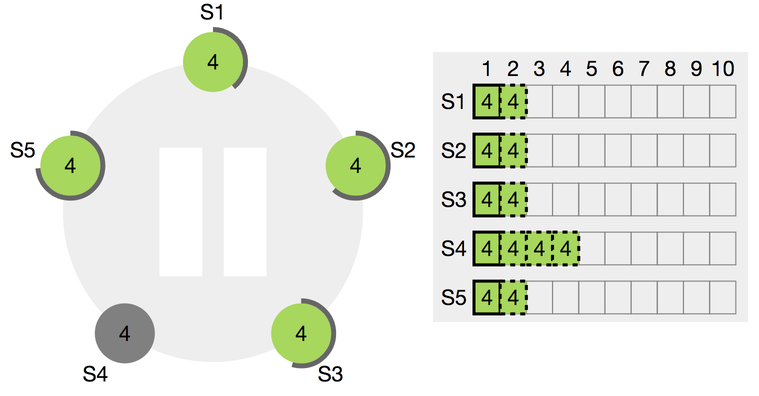
- 새로운 리더로 S1이 당선되고 Term 5가 시작됩니다.
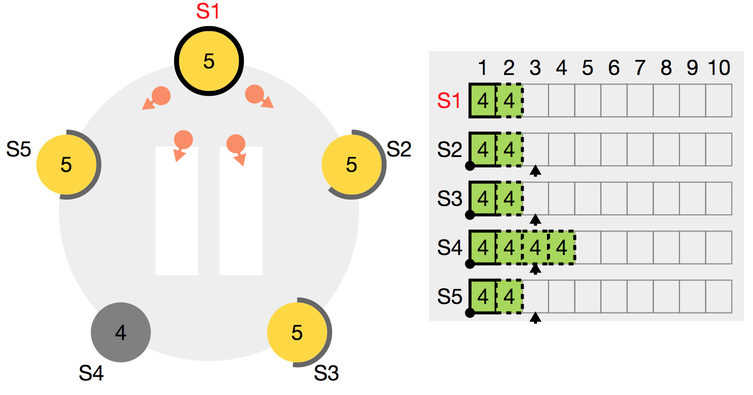
- S4가 정신을 차렸습니다! 그 와중에 Term 5의 리더 S1에 리퀘스트가 2통 들어왔네요.
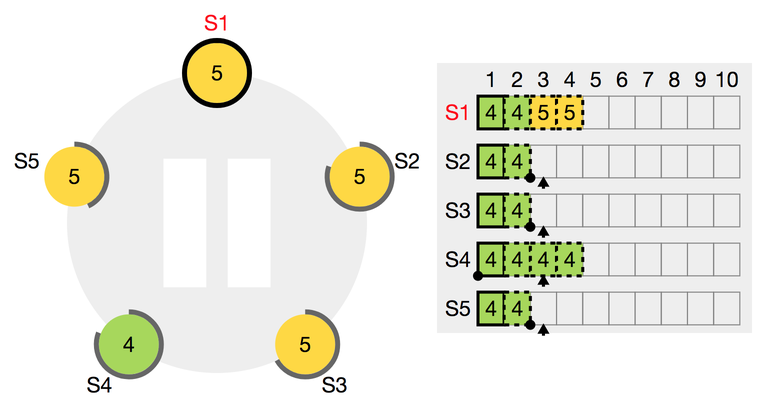
- S4는 리더와 로그를 일치시키기 위해 못 보냈던 로그를 지웁니다.
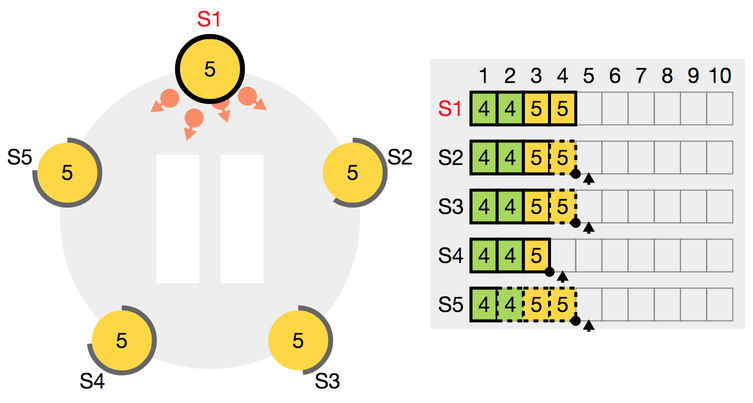
Log commit
로그 엔트리에 들어간 노드는 바로 노드의 State machine에 반영되는 것이 아닙니다. 일단 저장하고, 과반이 해당 로그를 받았다는 응답을 주면 State machine에 반영됩니다. 위 log store의 그림에서 실선 테두리를 가진 로그는 클러스터의 과반이 동의한 로그로 최종 state machine에 반영되는 로그인 반면, 점선 테두리를 가진 로그는 과반이 동의했는지 여부를 노드 입장에서 확신할 수 없어서 반영되지는 않고 저장만 된 로그를 의미합니다.
Next…
다음 포스트에서는 왜 Raft가 Fail-Recover 모델에서 안전하게 작동하는 알고리즘인지 증명하는 과정에 대해 다뤄보도록 하겠습니다.
References
이미지들은 직접 만든 이미지이거나 raft.github.io의 시뮬레이터 캡쳐, 혹은 원 논문의 figure를 가져왔습니다.