이 글은 USENIX ATC 2014에서 Best paper로 선정되었던 D. Ongaro et al.의 In Search of an Understandable Consensus Algorithm를 읽고 나름대로 제가 raft를 어떻게 이해했는지 정리해보는 글입니다.
이 글은 다음과 같은 시리즈로 작성될 예정입니다.
- 분산 시스템과 합의 알고리즘, 그리고 Raft의 디자인과 추구하는 방향
- Raft의 큰 그림: 용어 정의, 부분문제
- Raft의 부분 문제 - Leader Election, Log Replication
- Raft의 안정성 증명
- 다시 Raft의 큰 그림, Raft 평가, 그 외 기타 이슈
혹시 이 글에서 틀린 점이 있다면 코멘트 부탁드리겠습니다.
Restrictions on Raft
Priority on Leader Election
리더 선출 과정에서 최대한 로그를 많이 살릴 수 있도록 투표에 몇 가지 규칙을 적용합니다. 편의상 투표하는 노드를 A, RequestVote 를 통해 리더가 되려는 노드를 B라고 하겠습니다.
- B의 마지막 Log entry의 term number가 A의 마지막 Log entry의 것보다 높다면 무조건 B가 최신(up-to-date)라고 고려하고 B에 찬성표를 줍니다. 반대로, A의 마지막 Log entry의 term보다 낮은 term의 로그를 마지막 로그로 B가 갖고있다면 반대표를 줍니다. (term 우선)
- A와 B의 마지막 Log entry들의 term number가 같다면, 그동안 쌓은 로그의 개수를 대조합니다. B의 로그의 개수가 A의 로그의 개수보다 크거나 같으면 A는 B에게 찬성표를, 아니면 반대표를 던집니다.
정리하자면, term number가 높을 수록, term number가 같다면 로그의 길이(index)가 클 수록 리더가 될 가능성이 높아지는 것입니다.
Commitment of Log Entry
Log store와 Log commit이라는 단어를 여기서부터 다음과 같은 의미로 사용하도록 하겠습니다.
- Log store: 로그 엔트리를 단순히 저장함. Store만 된 로그가 실제 반영될지는 아직 확실하지 않은 상태
- Log commit: 받은 로그 엔트리를 확정적으로 받아들이고 노드의 state machine에 최종 반영
합의 문제에서 가장 중요한 것은 모든 노드가 동일한 상태에 있어야 한다는 점입니다. 즉, 똑같은 로그가 똑같은 순서대로 실행되어야 한다는 뜻입니다. Raft에서는 이를 위해 항상 Log Matching Property(같은 term, 같은 index면 동일한 로그라는 성질)를 유지시킵니다. Log Matching Property를 항상 만족시키기 위해, 저자들은 Log commit에 다음 조건을 추가합니다.
- term T에는 term T의 로그만 다수결로 commit 여부를 결정할 수 있다.
아래의 예제를 통해 왜 이런 조건을 추가했는지 알아봅시다.
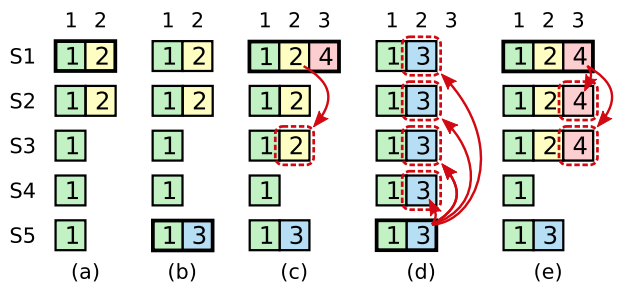
- (a) Term 2의 리더로 S1이 선출됐습니다! 리더가 된 뒤 request를 한 건 받았고, S2까지 log를 뿌렸으나…
- (b) 다른 서버에는 차마 로그를 뿌리지 못 하고 죽어버리고 말았습니다(ㅠㅠ) 새로운 리더로 S5가 선출됩니다. (S2는 반대, S3과 S4는 찬성표 + S5 자기 자신에게 찬성표)
- (c) S5가 Term 3의 request를 받았으나 아무 노드에게도 전해주지 못 하고 죽어버리고 말았습니다(ㅠㅠ) 그 사이 S1이 리더로 선출되었고, Term 4의 리더로 S1이 다시 당선됩니다. S1은 S3에게 term 2 / index 2의 로그를 전해준 상황입니다.
- (d) 만약 (c)에서 S1이 Term 4의 request를 받았으나 아무에게도 전해주지 못 한 채 죽어버렸다고 가정합시다. 새로운 리더로 선출될 수 있는 후보는 S5밖에 없습니다. 마지막 로그의 term number가 제일 높기 때문입니다. 이 경우 과반의 노드(S1, S2, S3)가 term 2 / index 2의 로그를 받았음에도 불구하고 commit되면 안 됩니다! S5가 더 최신 정보를 가진 노드이기 때문입니다.
- (e) 반대로 (c)에서 S1이 죽지 않고 성공적으로 과반의 노드에게 term 4 / index 3의 로그까지 복사했다고 합시다. term 4 / index 3까지의 로그를 성공적으로 복사했다는 것은 이전 index의 로그 엔트리까지도 역시 똑같은 로그로 복사했다는 것을 의미합니다. term 4 / index 3의 로그와 그 이전의 로그들은 이 시점에서 commit됩니다.
Proof of Safety
그래서 Raft가 진짜 안전할까요? 네. 안전합니다. 왜 안전한지를 이제부터 다뤄보고자 합니다. 증명은 먼저 Leader Completeness를 증명하고, State Machine Safety를 증명하는 순서로 이뤄집니다.
- Leader Completeness: commit된 로그는 리더도 무조건 갖고 있는 로그다.
- State Machine Safety: 클러스터 내의 어떤 서버가 자신의 state machine에 반영한 i번째 로그를 L[i]이라고 할 때, 이 L[i]를 i번째로 반영하지 않는 노드는 없다.
Leader Completeness
Term T, U, V (U > V > T)에 대해서
- Term T의 리더를 Leader[T], Term U의 리더를 Leader[U], Term V의 리더를 Leader[V]라고 하겠습니다.
- Leader[U]가 term T에 commit된 로그 L을 갖고있지 않은 상태라고 가정합니다.
- Leader[U]가 선출될 당시 Leader[U]는 로그 L을 갖고있지 않으며, 과반의 찬성표를 받았습니다.
- Leader[T]가 L을 커밋한 이유는, 클러스터 내의 과반의 노드가 L을 성공적으로 받았기 때문입니다.
- 비둘기집의 원리에 의해 Leader[U]에 찬성표를 던지며 L을 받은 노드 N이 존재한다는 사실을 알 수 있습니다.
- N이 L을 accept했다는 것은, Leader[T]의
AppendEntriesRPC가 Leader[U]의RequestVoteRPC보다 먼저 도착했다는 것을 의미합니다. 아니라면, L은 낮은 term의 로그이므로 무시했을 것입니다. - N은 L을 store하면서 Leader[U]에게 찬성표를 던집니다. 즉 Leader[U]는 적어도 N만큼 최신(up-to-date)입니다.
- “N 이상의 최신”이라는 두 가지 경우가 있습니다.
- N이 들고 있는 마지막 로그와 Leader[U]가 마지막 로그의 term number는 같지만, Leader[U]가 더 많은 로그를 갖고 있다.
- N이 term T까지의 로그만을 갖고 있는 반면, term V의 로그를 Leader[U]가 갖고있다.
- 위의 두 가지 케이스 모두 말이 안 됩니다.
- 1번 케이스는 우리가 지금까지 Log Matching Property를 만족하며 로그를 쌓아왔기 때문에 Leader[U]가 L을 가지고 있지 않을 리가 없습니다.
- 2번 케이스는 과반이 term V에 Leader[V]가 리더가 되는 데에 찬성했으므로, L에 동의한 노드의 수가 전체 노드의 수의 반을 넘을 수 없게 됩니다.
- 그래서 commit된 로그는 미래의 리더가 반드시 들고있을 수 밖에 없습니다.
이렇게 Leader completeness의 증명이 끝납니다.
State Machine Safety
- 위에서 증명한 Leader Completeness Property에 의해 commit된 로그는 미래의 리더가 반드시 들고있게 됩니다.
- 미래의 리더는 commit된 로그를 Log Matching Property에 맞춰 똑같은 순서대로 로그를 전파합니다.
- Raft에서는 받은 로그를 index 순으로 반영하도록 강제하고 있기 때문에, 모든 노드는 결국 같은 로그를 같은 순서로 반영하게 될 것입니다.
State Machine Safety의 증명은 이렇게 끝납니다. 위 증명을 통해 모든 노드가 결국 같은 output을 낸다는 것을 보장할 수 있습니다.

Next
지금까지 Raft의 큰 부분을 다뤘습니다. 지금까지 다룬 내용들을 3줄 요약하자면 다음과 같습니다.
- 모든 알려진 Peer에 대해서,
- 모든 정직한 Peer에 대해서 (Fail-Recover),
- Raft로 Consensus를 이룰 수 있다!
다음 글에서는 논문에서는 가볍게 언급된 부분과 이슈들, 그리고 저자들의 Raft에 대한 평가와 제 개인적인 생각들을 정리해서 올려보고자 합니다. 다음 글이 마지막이 되겠네요 :)
References
이미지들은 직접 만든 이미지이거나 raft.github.io의 시뮬레이터 캡쳐, 혹은 원 논문의 figure를 가져왔습니다.