이 글은 USENIX ATC 2014에서 Best paper로 선정되었던 D. Ongaro et al.의 In Search of an Understandable Consensus Algorithm를 읽고 나름대로 제가 raft를 어떻게 이해했는지 정리해보는 글입니다.
이 글은 다음과 같은 시리즈로 작성될 예정입니다.
- 분산 시스템과 합의 알고리즘, 그리고 Raft의 디자인과 추구하는 방향
- Raft의 큰 그림: 용어 정의, 부분문제
- Raft의 부분 문제 - Leader Election, Log Replication
- Raft의 안정성 증명
- 다시 Raft의 큰 그림
혹시 이 글에서 틀린 점이 있다면 코멘트 부탁드리겠습니다.
Basics
Raft를 다루기 전에 부분문제를 설명하기 위한 용어들을 몇 가지 정의하고, 필요한 개념을 짚고 넘어가고자 합니다.
Server state
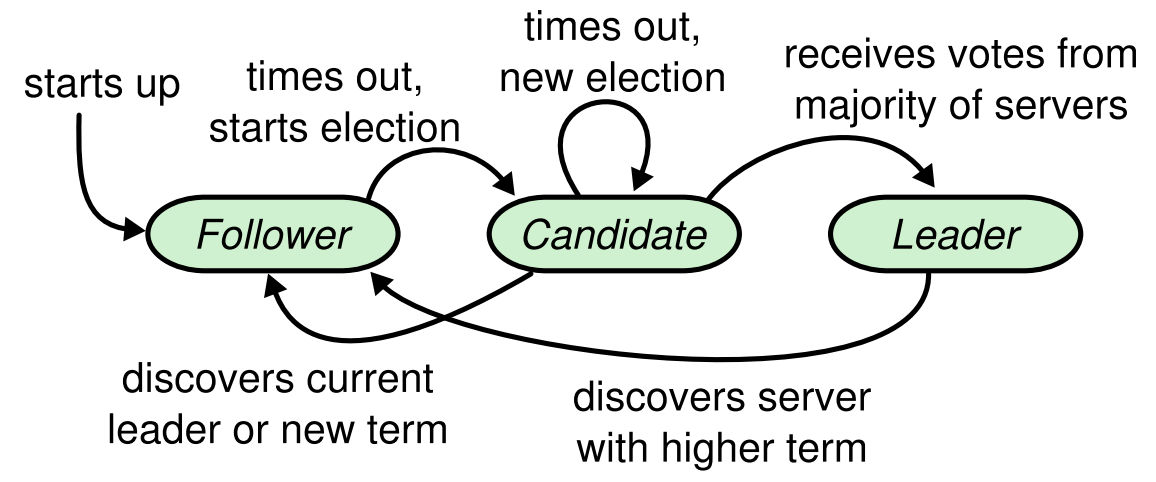
Raft로 운용되는 클러스터 안의 노드는 위의 State machine을 따릅니다.
-
Leader
Raft에서 리더는 클라이언트로부터 request를 받고 이를 클러스터 안의 모든 노드에게 전파하는 역할을 합니다. 이 때 리더노드는
AppendEntries라는 RPC 콜을 이용하고, 이 RPC 콜은 리더만 부를 수 있습니다. 즉, Raft에서 클러스터의 모든 노드에 로그를 붙일 수 있는 것은 리더 뿐입니다. -
Follower
처음 노드가 시작될 때 노드의 모드고, 이 상태에서는 리더로부터
AppendEntries라는 RPC 콜을 받습니다.AppendEntries라는 콜의 역할은 두 가지 입니다. 첫째로는AppendEntries라는 말 그대로 로그 엔트리를 노드에 붙이라는 명령입니다. 두 번째로는 Heartbeat의 용도입니다.AppendEntries는 리더 노드만 호출하는 RPC 콜입니다. 정해진 시간 내로 리더가AppendEntries를 호출하지 않으면 리더가 죽었다고 판단할 수 있습니다. -
Candidate
Follower 노드가 일정 시간동안 리더로부터
AppendEntries콜을 받지 못 하면 도달하는 상태입니다.RequestVote라는 RPC 콜을 통해 클러스터의 모든 노드에게 브로드캐스트하고, 노드 과반수 이상의 동의를 얻으면 리더가 됩니다. 바로 리더가 되지 않는 경우는 두 가지가 있습니다. (1) 다른 새로운 리더의 선출을 발견하면 리더 후보를 포기하고 Follower로 돌아갑니다. (2) 과반수 이상의 동의를 얻지는 못 한 채로 일정시간이 지나면 다시RequestVote콜을 통해 투표를 요청합니다.
Term
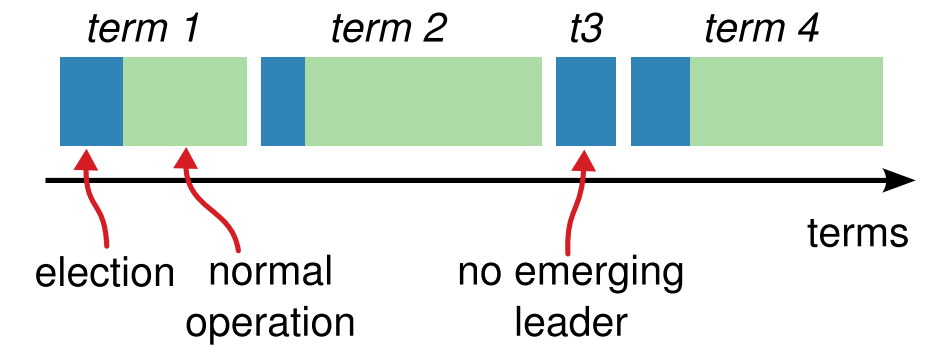
Term은 어떤 노드가 리더로서 작동하는 구간을 말합니다. 즉, 각 term은 (1) 리더 선출 과정과 (2) 리더 선출 이후 다음 리더 선출 전까지의 정상 작동 구간을 포함합니다. 위 그림의 term t3의 경우, 어떠한 노드도 모종의 이유로 과반수의 동의를 얻지 못 해, 리더 선출 없이 끝나는 경우를 보여줍니다.
Subproblems of Raft
이 논문에서는 Consensus라는 큰 문제를 세 가지 부분문제로 나눠 해결합니다.
Leader Election
언제나 리더는 있어야만 하며, 리더가 작동을 멈출 경우 항상 리더를 선출해야 합니다. 이 문제에서는 리더를 선출하는 방식에 대해 다룹니다.
Log Replication
리더는 클라이언트로부터 로그를 받고, 모든 클러스터의 노드에게 같은 로그를 복사하여 승인하도록 합니다. 이 문제에서는 리더가 클라이언트로 받은 로그가 어떻게 클러스터의 모든 노드에게 전파되는지를 다룹니다.
Safety Argument
클러스터 안의 노드들이 같은 순서로 같은 명령을 실행해야 클러스터 내의 노드간 합의가 이뤄졌다고 말할 수 있습니다. 이 문제에서는 어떻게 Raft 알고리즘으로 올바른 합의를 만드는지에 대해 다룹니다.
Invariants of Raft
저자는 Raft를 올바르게 구현한다면 아래와 같은 성질이 변함없이 모두 만족됨을 보장한다고 언급합니다.
- Election Safety: 클러스터 안에 최대 1개까지 노드가 존재할 수 있음
- Leader Append-Only: 리더는 절대로 로그를 덮어쓰거나 삭제하지 않고 새 엔트리를 추가하기만 함
- Log Matching: 서로 다른 두 노드에서 같은 인덱스를 갖는 로그가 같은 term에 쓰여진 로그라면, 두 로그는 완전히 동일한 로그임
- Leader Completeness: 어떤 두 term T, U(U > T)에 대해, T에 커밋된 로그는 term U에서의 리더의 로그에도 커밋되어있음
- State Machine Safety: 클러스터 내의 임의의 서버 S1이 자기 서버의 Log[i]를 커밋했다면, 다른 모든 서버들의 Log[i]도 S1의 Log[i]와 일치하여 결론적으로 같은 명령을 수행함.
위에서 언급한 부분문제 3번(Safety Argument)는 (1)위의 성질이 왜 만족되는지 증명하고, (2)이 성질들을 만족할 때 왜 Raft가 맞는지 증명하는 순서로 해결됩니다. 위의 성질 이름을 기억해두시면 다음 포스트를 읽는 데에 도움이 될 것입니다. 어떻게 저자들이 Raft의 Correctness를 증명하는지는 다음 포스트에서 작성해보도록 하겠습니다.
References
이미지들은 직접 만든 이미지이거나 원 논문의 figure를 가져왔습니다.